Demo 2: Differentiabilitet#
Demo af Christian Mikkelstrup, Hans Henrik Hermansen, Karl Johan Måstrup Kristensen og Magnus Troen. Revideret marts 2026 af shsp.
from sympy import *
from dtumathtools import *
init_printing()
Når det kommer til Python/CAS og differentiabilitet, er vi i samme situation som med kontinuitet. Python/CAS er ikke egnet til at bevise differentiabilitet. Det kan dog være et stærkt værktøj, når først differentiabilitet er bevist. I denne demo vil vi vise, hvordan Python kan være til stor nytte i arbejde med differentiable funktioner.
At definere og evaluere vektorfunktioner#
Vektorfunktioner af flere variable som defineret i lærebogen kan skrives som
hvor koordinatfunktionerne \(f_1,\ldots,f_k\) i outputtet er skalarfunktioner.
I Sympy kan vektorfunktioner konstrueres ved brug af Matrix-objektet:
x1, x2, x3 = symbols('x1:4')
f_udtryk = Matrix([
x1 * sin(x2) + x3**2,
x1*x2*x3,
x1**2 + 4*x2 * x3
])
f_udtryk
Vi kan evaluere denne vektorfunktion i et udvalgt input ved brug af .subs():
f_udtryk.subs({x1: 1, x2: 2, x3: 3})
Bemærk, at dette faktisk blot viser, at .subs() udfører substitutionen på alle elementer i en vektor. Hvis du foretrækker at definere matematiske funktioner som Python-funktioner, kan det samme opnås med
def f(x1, x2, x3):
return Matrix([
x1 * sin(x2) + x3**2,
x1*x2*x3,
x1**2 + 4 * x2 * x3
])
f(x1,x2,x3)
f(1,2,3)
Begge tilgange giver samme resultat. Benyt den metode, du føler mest for.
Gradientvektoren#
Et eksempel på en vektorfunktion er gradienten af en skalarfunktion \(f:\Bbb R^n\to\Bbb R\):
Den kan opfattes som en afbildning \(\nabla f: \mathbb R^n \to \mathbb R^n\). I demo 1 viste vi, hvordan gradienten af en skalarfunktion kan fortolkes og visualiseres som et vektorfelt. Det er muligt, netop fordi dens antal koordinatfunktioner i outputtet er lig antallet af variable i dens input, her begge \(\Bbb R^n\).
Som et eksempel kan vi betragte gradienten af en funktion \(f: \mathbb{R}^2 \to \mathbb{R}\) defineret ved \(f(\boldsymbol{x}) = 1 - \frac{x_1^2}{2} -\frac{x_2^2}{2}\):
x1, x2 = symbols('x1:3')
f = 1 - x1**2 / 2 - x2**2 / 2
Nabla = dtutools.gradient(f)
f, Nabla
Vi ser her, at gradienten \(\nabla f: \mathbb R^2 \to \mathbb R^2\) er givet ved \(\nabla f(x_1, x_2) = (-x_1, -x_2)\). En evaluering i et punkt som fx \(\boldsymbol{x}_0 = (1, -1)\) betyder, at specifikke gradientvektor tilhørende dette punkt skal findes:
Nabla.subs({x1: 1, x2: -1})
Retningsafledte#
Betragt igen funktionen \(f: \mathbb{R}^2 \to \mathbb{R}\) med forskriften \(f(\boldsymbol{x}) = 1 - \frac{x_1^2}{2} -\frac{x_2^2}{2}\).
Vi vil gerne finde den retningsafledte af \(f\) i et punkt \(\boldsymbol{x_0} = (1,-1)\), altså hældningen fra punktet på grafen, i retningen udpeget af retningsvektoren \(\boldsymbol{v}=(-1,-2)\).
x0 = Matrix([1,-1])
v = Matrix([-1,-2])
x0, v
Lærebogen giver os følgende formel for den retningsafledte, der består af et indre produkt:
hvor \(\boldsymbol e\) repræsenterer en enhedsretningsvektor, altså en retningsvektor med en størrelse på \(1\). Lad os derfor først normalisere \(\boldsymbol v\) fx ved brug af kommandoen .normalize() (alternativt kan man finde og dividere med normen):
e = v.normalized()
e
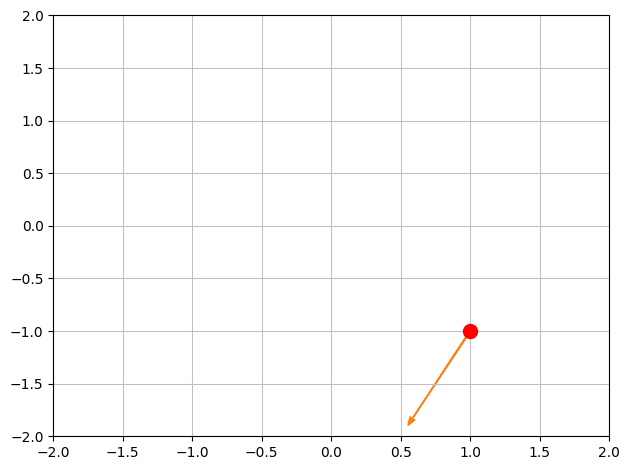
Lad os lave et hurtigt plot for at se punktet og retningen i definitionsmængden:
p1 = dtuplot.scatter(x0, rendering_kw={"markersize":10,"color":'r'}, xlim=[-2,2],ylim=[-2,2],show=False)
p1.extend(dtuplot.quiver(x0,e,show=False))
p1.show()
Den næste komponent, vi skal bruge, er gradienten af \(f\) i \(\boldsymbol{x_0}\):
Nabla = Matrix([diff(f,x1),diff(f,x2)]).subs({x1:x0[0],x2:x0[1]})
Nabla
Vi har nu alle nødvendige komponenter klar. Da vi har med reelle vektorer at gøre (fra \(\Bbb R^n\)), udregnes det indre produkt som det sædvanlige prikprodukt, \(\nabla_{\boldsymbol{e}} f(\boldsymbol{x_0}) = \braket{\boldsymbol{e},\nabla f(\boldsymbol{x_0})}=\boldsymbol{e}\cdot \nabla f(\boldsymbol{x_0})\):
e.dot(Nabla)

Hessematricen#
De andenordens partielt afledte af skalarfunktioner bliver vigtige senere i kurset (til ekstremumkarakteristik og Taylor-udvikling). Lærebogen samler alle andenordens partielt afledte i en matrix kaldet en Hessematrix.
Lad os betragte følgende skalarfunktion i tre variable:
f = 1-x1**2/2-x2**3/2*x3 + x1*x3
f

Dens Hessematrix konstrueres manuelt som følger:
fx1x1 = f.diff(x1,2)
fx1x2 = f.diff(x1,x2)
fx1x3 = f.diff(x1,x3)
fx2x2 = f.diff(x2,2)
fx2x3 = f.diff(x2,x3)
fx3x3 = f.diff(x3,2)
H1 = Matrix([
[fx1x1, fx1x2, fx1x3],
[fx1x2, fx2x2, fx2x3],
[fx1x3, fx2x3, fx3x3]
])
H1
Eller vi kan være hurtigere og bruge .hessian-kommandoen fra dtutools-pakken:
H2 = dtutools.hessian(f)
H2
I begge tilfælde evalueres Hessematricen i et udvalgt punkt med .subs():
H1.subs({x1:1,x2:2,x3:3}), H2.subs({x1:1,x2:2,x3:3})
Jacobimatricen#
Da en vektorfunktions koordinatfunktioner selv er skalarfunktioner, har hver koordinatfunktion en gradient. Lærebogen samler alle disse gradienter som rækker i en ny matrix kaldet vektorfunktionens Jacobimatrix:
Betragt for eksempel vektorfunktionen \(\boldsymbol{f}: \mathbb{R}^4 \to \mathbb{R}^3\) givet ved:
x1,x2,x3,x4 = symbols('x1:5', real = True)
f = Matrix([
x1**2 + x2**2 * x3**2 + x4**2 - 1,
x1 + x2**2/2 - x3 * x4,
x1 * x3 + x2 * x4
])
f
Bemærk, at \(f_1, f_2,f_3\) er differentiable skalarfunktioner for alle \(\boldsymbol{x} \in \mathbb R^4\). Jacobimatricen for \(\boldsymbol f\) kan findes ved manuelt at samle gradienterne:
J_f = Matrix.vstack(dtutools.gradient(f[0]).T, dtutools.gradient(f[1]).T, dtutools.gradient(f[2]).T)
J_f
eller vha. Sympys .jacobian-kommando:
J = f.jacobian([x1,x2,x3,x4])
J
Tangenter til parameterkurver#
Betragt vektorfunktionen \(\boldsymbol r : [0,4\pi]\to\Bbb R^2\) givet ved
u = symbols('u', real=True)
r = Matrix([u*cos(u), u*sin(u)])
r
Fortolker vi denne vektorfunktion som en parameterfremstilling for et geometrisk område (en punktmængde), så repræsenterer den en spiral i planen. Til at plotte parameterfremstillinger har vi kommandoen plot_parametric:
dtuplot.plot_parametric(r[0], r[1],(u,0,4*pi),rendering_kw={"color":"red"},use_cm=False)
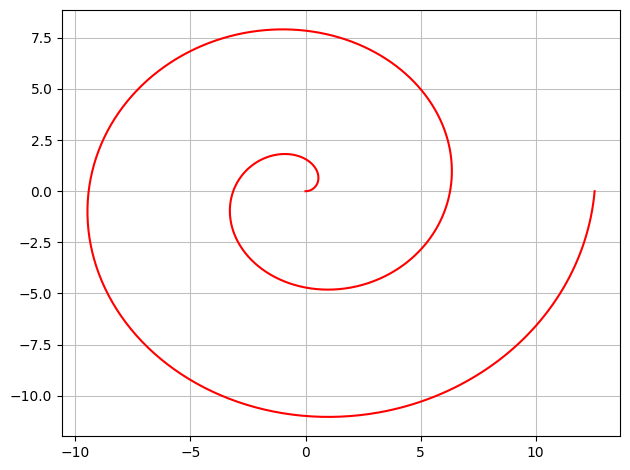
<spb.backends.matplotlib.matplotlib.MatplotlibBackend at 0x7f298a2fe9d0>
Med blot én inputvariabel \(u\) får Jacobimatricen for \(\boldsymbol r\) blot én søjle:
rd = r.jacobian([u])
rd
Bemærk, at med kun én variabel er de partielt afledte blot sædvanlige ordinært afledte. .jacobian-kommandoen er derfor ikke nødvendig, da vi blot kan differentiere vektorfunktionen med den almindelige .diff-kommando, som udføres på hvert element, når den anvendes på en vektor:
rd = diff(r,u)
rd
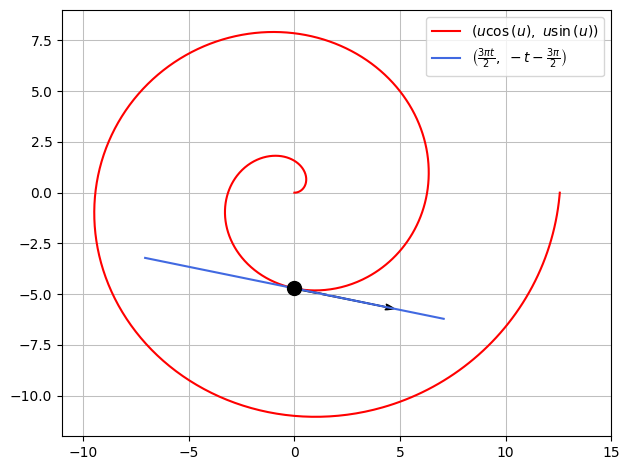
Da \(\boldsymbol r\) opfattes som en parameterkurve, svarer dens Jacobimatrix faktisk til en tangentvektor til kurven. Lad os benytte den til at konstruere tangentlinjen til spiralen i \((0,-\frac{3\pi}{2})\). Dette punkt svarer til parameterværdien \(u_0 = \frac{3\pi}{2}\):
u0 = 3*pi/2
ru0 = r.subs(u,u0)
ru0
Tangentvektoren fra dette punkt er dermed:
rdu0 = rd.subs(u,u0)
rdu0
Vi kan nu plotte denne tangentvektor som den er, eller vi kan konstruere hele den fulde tangentlinje som en parameter fremstilling:
t = symbols('t', real=True)
T = ru0 + t*rdu0
T
Et samlet plot:
p = dtuplot.plot_parametric(r[0], r[1],(u,0,4*pi),rendering_kw={"color":"red"},use_cm=False,show=False)
p.extend(dtuplot.plot_parametric(T[0],T[1],(t,-1.5,1.5),rendering_kw={"color":"royalblue"},use_cm=False,show=False))
p.extend(dtuplot.scatter(ru0,rendering_kw={"markersize":10,"color":'black'}, show=False))
p.extend(dtuplot.quiver(ru0,rdu0,rendering_kw={"color":"black"},show=False))
p.xlim = [-11,15]
p.ylim = [-12,9]
p.show()