Uge 1: Øvelser#
Opgaverne er håndregningsopgaver med mindre andet er angivet (fx at du bliver bedt om at plotte en graf eller udregne en eksponentialfunktion).
Opgaver – Store Dag#
1: Funktion eller ej?#
Betragt følger korrespondance mellem \(a\) og \(b\) værdier:
\(a\) |
\(b\) |
|---|---|
1 |
0 |
2 |
1 |
0 |
3 |
1 |
2 |
Vi betragter funktioner hvis definitionsmængde (domain) er en delmængde af \(\{0,1,2,3\}\) og hvis dispositionsmængde (co-domain) er \(\{0,1,2,3\}\). Vi skal bestemme om \(f\) og \(g\) definerer funktioner, hvis vi lader \(f\) følge reglen at første søjle (\(a\)-værdierne) er input og anden søjle (\(b\)-værdierne) skal være output af funktionen \(f\) og definitionsmængden er \(\{0,1,2\}\); og vi lader \(g\) følge reglen om at anden søjle er input og første søjle skal være output af funktionen \(g\) med definitionsmængde \(\{0,1,2,3\}\).
Definerer \(f\) en funktion? Gør \(g\)? I bekræftende fald: bestem værdimængden/billedmængden (engelsk: range/image) for funktionen, og afgør om funktionen er injektiv og surjektiv.
Hint
Læs dette afsnit i noten
Svar
Kun \(g\) er en funktion, da \(f\) både forsøger at definere \(f(1)=0\) og \(f(1)=2\). Funktionen \(g\) har \(\operatorname{im}(g) = \{0,1,2\} \subset \{0,1,2,3\}\) er derfor ikke surjektiv. Da \(g(0)=1\) og \(g(2)=1\) er den heller ikke injektiv.
2: Ens funktionsforskrifter?#
Vi betragter funktioner \(f_i : \mathbb{R} \to \mathbb{R}\) givet ved:
hvor \(x \in \mathbb{R}\).
Nogle af funktionerne er samme funktion. Find dem alle!
Hint
ReLU er defineret i lærebogen.
Hint
Find først \(f_i(x)\) for de forskellige funktioner for et par forskellige værdier af \(x\).
3: Funktion med ukendt forskrift#
Betragt en funktion \(f: \mathbb{R} \to \mathbb{R}\) hvorom der gælder \(\lim_{x \to 2} f(x) = 5\) og \(f(2) = 3\). Hvad kan vi sige om \(f\) i punktet \(x=2\)? Vælg det korrekte svar:
Funktionen er kontinuert i punktet \(x=2\).
Funktionen er differentiabel i punktet \(x=2\).
Funktionen er diskontinuert i punktet \(x=2\).
Funktionen er ikke veldefineret i punktet \(x=2\).
Man kan ikke afgøre ovenstående, da funktionsforskriften ikke er angivet!
4: Ikke-linearitet af ReLU#
Betragt ReLU-funktionen, \(\operatorname{ReLU}: \mathbb{R}^n \to \mathbb{R}^n\). Forklar hvorfor funktionen ikke er lineær.
Hint
Husk at lineære afbildninger \(L: \mathbb{R}^n \to \mathbb{R}^n\) (se Mat1a-bogen) skal opfylde to linearitetsbetingelser. Skriv dem ned.
Hint
Find vektorer i \(\mathbb{R}^n\) og/eller skalarer i \(\mathbb{R}\), hvor disse betingelser ikke gælder. Det er ikke nok at skrive “ReLU er ikke lineær, da det ikke opfylder de to linearitetsbetingelser”. Du skal vise at de ikke er opfyldt.
5: Mulige visualiseringer#
Diskuter om man kan visualisere nedenstående funktioner – i givet fald plot dem med SymPy/dtumathtools:
En skalarfunktion af to variable \(f: \mathbb{R}^2 \to \mathbb{R}, \, f(x_1,x_2) = \sqrt{\vert x_1 x_2 \vert}\)
En skalarfunktion af fire variable \(f: \mathbb{R}^4 \to \mathbb{R}, \, f(x_1,x_2,x_3,x_4) = \sqrt{\vert x_1 x_2 x_3 x_4 \vert}\)
En kompleks skalarfunktion af to variable \(f: \mathbb{R}^2 \to \mathbb{C}, \, f(x_1,x_2) = \sqrt{\vert x_1 x_2 \vert} + i \cos(x_1 + x_2)\)
Et vektorfelt i 2D \(\pmb{f}: \mathbb{R}^2 \to \mathbb{R}^2, \, \pmb{f}(x_1,x_2) = (-x_2/3, x_1/3)\)
Et vektorfelt i 3D \(\pmb{f}: \mathbb{R}^3 \to \mathbb{R}^3, \, \pmb{f}(x,y,z)= (x^3+yz^2, y^3-xz^2, z^3)\)
En funktion af formen \(\pmb{r}: [0,10] \to \mathbb{R}^3, \, \pmb{r}(t) = (\cos(t),\sin(t),t)\)
Note
Følgende Python kommandoer kan være nyttige:
dtuplot.plot3d, dtuplot.plot_vector,
dtuplot.plot3d_parametric_line.
Hint
Når man plotter et vektorfelt, kan det være nødvendigt at skalere vektorerne (hvis de er for korte eller lange). Dette kan gøres ved at gange vektorfeltet igennem med en skalar, fx 0.1 * f i stedet for f eller smartere vha. keywords in fx dtuplot.plot_vector(..., quiver_kw={"length":0.005,"color":"black"})
6: Evaluering af et Neuralt Netværk#
Betragt et simpelt “shallow” neuralt netværk \(\pmb{\Phi}: \mathbb{R}^2 \to \mathbb{R}\) med ét skjult lag (\(L=2\)). Netværket er defineret ved parametrene:
hvor aktiveringsfunktionen i det skjulte lag er ReLU-funktionen, \(\pmb{\sigma}(\pmb{z}) = \operatorname{ReLU}(\pmb{z})\), mens aktiveringsfunktionen i det sidste lag er identitetsafbildningen \(\pmb{\sigma}(\pmb{z}) = \pmb{z}\). Netværksfunktionen er altså givet ved:
Spørgsmål a#
Beregn værdien af netværket i punktet \(\pmb{x} = \begin{bmatrix} 0.5 \\ 1 \end{bmatrix}\).
Hint
Start med at beregne den affine transformation i første lag: \(\pmb{z}_1 = A_1 \pmb{x} + \pmb{b}_1\). Herefter anvendes ReLU på resultatet (anvendt elementvis). Til sidst ganges med \(A_2\) og \(b_2\) lægges til.
Svar
Vi starter med det indre udtryk (første lag):
Nu anvendes aktiveringsfunktionen (ReLU):
Til sidst beregnes outputtet (andet lag):
Så \(\pmb{\Phi}(0.5, 1) = 1\).
Spørgsmål b#
Find et punkt \(\pmb{x}\), hvor netværkets output \(\pmb{\Phi}(\pmb{x})\) er negativt. Begrund dit svar.
Hint
Kig på output-laget \(A_2 = [-1, 2]\). For at få et negativt resultat skal det første element i det skjulte lag (som ganges med -1) være stort, mens det andet element (som ganges med 2) skal være lille eller nul. Prøv at finde en \(\pmb{x}\), der opfylder dette.
Spørgsmål c#
Hvor mange justerbare parametre (vægte og bias-værdier) har dette netværk totalt?
Hint
For et lag \(\ell\) med input-dimension \(n_{\ell-1}\) og output-dimension \(n_\ell\) er der \(n_\ell \cdot n_{\ell-1}\) vægte (elementer i matricen \(A_\ell\)) og \(n_\ell\) bias-værdier (elementer i vektoren \(\pmb{b}_\ell\)). Her er \(n_0 = 2\), \(n_1 = 2\) og \(n_2 = 1\).
Svar
Vi tæller parametrene lag for lag:
Lag 1: Matrix \(A_1\) er \(2 \times 2\) (4 parametre), bias \(\pmb{b}_1\) er \(2 \times 1\) (2 parametre). I alt \(4+2=6\).
Lag 2: Matrix \(A_2\) er \(1 \times 2\) (2 parametre), bias \(b_2\) er \(1 \times 1\) (1 parameter). I alt \(2+1=3\).
Det totale antal parametre er \(6 + 3 = 9\).
Spørgsmål d#
Vi erstatter nu aktiveringsfunktionen (ReLU) med en “hard limiter” funktion (en variant af signum-funktionen), som vi kalder \(\sigma_{\text{step}}\).
Som skalar-funktion \(\sigma_{\text{step}}: \mathbb{R} \to \mathbb{R}\) er den defineret ved:
Som vektorfunktion \(\pmb{\sigma}_{\text{step}}: \mathbb{R}^n \to \mathbb{R}^n\) defineres den ved at anvende skalarfunktionen på hver koordinat:
Betragt nu netværket med denne nye aktiveringsfunktion: \(\pmb{\Phi}(\pmb{x}) = A_2 \pmb{\sigma}_{\text{step}}(A_1 \pmb{x} + \pmb{b}_1) + b_2\).
Angiv den delmængde af definitionsmængden, hvor netværksfunktionen \(\pmb{\Phi}(\pmb{x})\) er diskontinuert.
Hint
Definitionsmængden er \(\mathbb{R}^2\), så vi leder efter en delmængde af planen. Husk at en affin funktion \(\pmb{z} \mapsto A \pmb{z} + \pmb{b}\) er kontinuert for alle valg af matrix \(A\) og vektor \(\pmb{b}\).
Hint
Funktionen \(\sigma_{\text{step}}(z)\) “hopper” (er diskontinuert), præcis når inputtet \(z\) er \(0\). Da \(\pmb{\sigma}_{\text{step}}\) anvendes elementvis på vektoren \(\pmb{z} = A_1 \pmb{x} + \pmb{b}_1\), vil netværket være diskontinuert der, hvor en (eller flere) af elementerne i \(\pmb{z}\) er 0. Opstil en ligning for hver element i \(\pmb{z}\) og opstil et udtryk for “diskontinuitets”-mængden.
7: Visualisering af Netværket#
I denne opgave skal du bruge Python til at visualisere funktionen \(\pmb{\Phi}(\pmb{x})\) fra forrige opgave 6: Evaluering af et Neuralt Netværk (med ReLU som aktiveringsfunktion).
Du skal plotte grafen for netværket over området \(x_1, x_2 \in [-2, 2]\). Vi benytter her en numerisk tilgang (med Matplotlib) frem for SymPy for at opnå en bedre 3D-visualisering. Kør koden nedenfor – det er ikke nødvendigt at sætte sig ind i de Python-tekniske detaljer.
import numpy as np
import matplotlib.pyplot as plt
# Parametre
A1 = np.array([[2, 0],
[-1, 1]])
b1 = np.array([[-1],
[0]])
A2 = np.array([[-1, 2]])
b2 = 0
def ReLU(x):
return np.maximum(x, 0)
def shallow_nn(x1, x2):
# inputtet samles i en vektor x
vals = np.zeros(x1.shape)
for i in range(x1.shape[0]):
for j in range(x1.shape[1]):
x_vec = np.array([[x1[i,j]], [x2[i,j]]])
# Lag 1: Affin transformation + ReLU
z1 = A1 @ x_vec + b1
a1 = ReLU(z1)
# Lag 2: Affin transformation
output = A2 @ a1 + b2
vals[i,j] = output[0,0]
return vals
x_range = np.linspace(-2, 2, 80)
y_range = np.linspace(-2, 2, 80)
X, Y = np.meshgrid(x_range, y_range)
Z = shallow_nn(X, Y)
# Plot
fig = plt.figure(figsize=(12, 8))
ax = fig.add_subplot(111, projection='3d')
surf = ax.plot_surface(X, Y, Z, cmap='viridis',
edgecolor='k', linewidth=0.3, alpha=0.5,
rcount=20, ccount=20, antialiased=True)
# "Knæk-linjerne" (hvor ReLU går fra 0 til positiv)
y_vals = np.linspace(-2, 2, 100)
x_vals_1 = np.full_like(y_vals, 0.5)
z_vals_1 = shallow_nn(np.array([x_vals_1]), np.array([y_vals]))[0]
x_vals_2 = np.linspace(-2, 2, 100)
y_vals_2 = x_vals_2
z_vals_2 = shallow_nn(np.array([x_vals_2]), np.array([y_vals_2]))[0]
ax.plot(x_vals_1, y_vals, z_vals_1, color='red', linewidth=3, label='$2x_1 - 1 = 0$ (Knæk 1)')
ax.plot(x_vals_2, y_vals_2, z_vals_2, color='orange', linewidth=3, label='$-x_1 + x_2 = 0$ (Knæk 2)')
ax.set_xlabel('$x_1$')
ax.set_ylabel('$x_2$')
ax.set_zlabel('$\Phi(x)$')
ax.legend()
ax.view_init(elev=15, azim=-100)
plt.tight_layout()
plt.show()
Show code cell output
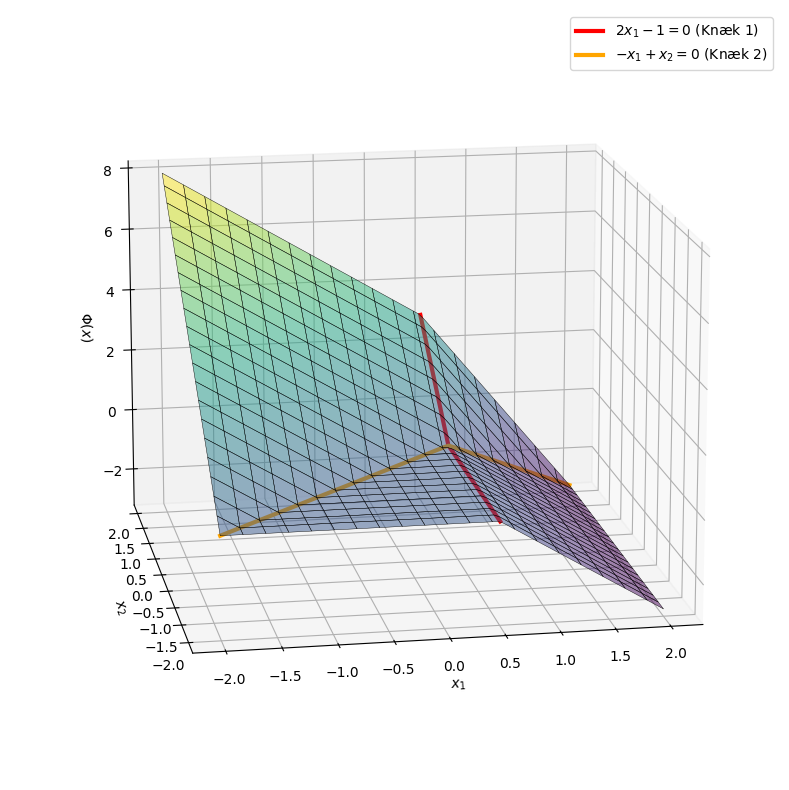
Note
Læg mærke til, at grafen består af plane flader, der er “knækket” og sat sammen. Dette skyldes ReLU-funktionen, som er stykkevis lineær. I store netværk der anvendes i praksis sættes millioner af sådanne lineære underrum sammen.
Kan du plotte grafen af det samme neurale netværk hvor \(\pmb{\sigma}_{\text{step}}\) bruges i stedet for ReLU? Planerne i den nye graf bør ikke “hænge sammen” (hvorfor?).
Hint
Brug np.where(x >= 0, 1, -1) i stedet for ReLUs np.maximum(x, 0).
8: Lineær vektorfunktion#
Lad \(A \in \mathsf{M}_{3 \times 5}(\mathbb{R})\) være givet ved
Betragt vektorfunktionen \(\pmb{f}: \mathbb{R}^5 \to \mathbb{R}^3\) givet ved \(\pmb{f} = \pmb{x} \mapsto A\pmb{x}\), hvor \(\pmb{x}\) er en søjlevektor i \(\mathbb{R}^5\).
Spørgsmål a#
Angiv de 3 koordinatfunktioner for \(\pmb{f}\).
Hint
Husk at koordinatfunktionerne \(f_i\) er \(\pmb{f} = (f_1,f_2,f_3)\).
Spørgsmål b#
Angiv billedmængden \(\operatorname{im}(\pmb{f})\) for \(\pmb{f}\).
Hint
Hvad er rangen af \(A\)? Hvad er søjlerummet (column space \(\operatorname{col}A\)) af \(A\)?
Svar
\(\operatorname{im}(\pmb{f}) = \operatorname{col}A = \mathbb{R}^3 \)
Spørgsmål c#
Er vektorfunktionen \(\pmb{f}\) surjektiv og/eller injektiv?
Svar
\(\pmb{f}\) er surjektiv, da \(\operatorname{im}(\pmb{f}) = \mathbb{R}^3\). Den er ikke injektiv, da \(\operatorname{dim ker}(A) = 5-3=2\) (du bør finde to forskellige vektorer \(\pmb{x}_1, \pmb{x}_2 \in \mathbb{R}^5\) for hvilke \(\pmb{f}(\pmb{x}_1) = \pmb{f}(\pmb{x}_2)\)).
9: Næste primtal-funktion (frivillig)#
Dette er en valgfri ekstraopgave.
Lad \(f: \mathbb{N} \to \mathbb{N}\) være en funktion, der returnerer det næste primtal (strengt) større end et givet naturligt tal \(n\). I denne opgave skal du først vurdere værdien af funktionen for to specifikke input og derefter vise, at funktionen er veldefineret, før du implementerer den i Python.
Spørgsmål a#
Find ved simple overvejelser \(f(10)\) og \(f(13)\).
Hint
Overvej primtallene efter \(n\): 2, 3, 5, 7, …
Svar
\(f(10) = 11\) og \(f(13) = 17\), da 11 er det mindste primtal større end 10, og 17 er det mindste primtal større end 13.
Spørgsmål b#
Argumenter for, at funktionen \(f(n)\) er veldefineret.
Hint
Dette betyder, at vi skal argumentere for at afbildningen \(f: \mathbb{N} \to \mathbb{N}\) er en funktion, altså, at den til ethvert element \(n \in \mathbb{N}\) entydigt knytter præcis ét element \(f(n) \in \mathbb{N}\).
Hint
Der findes uendeligt mange primtal og således uendeligt store primtal.
Svar
Eksistens: Der findes uendeligt mange primtal, så der vil altid være et primtal større end ethvert naturligt tal.
Entydighed: For ethvert tal \( n\) findes der et entydigt mindste primtal, der er større end \( n\).
Funktionen er derfor veldefineret, da der altid findes et næste primtal større end \( n\) (eksistens), og da der kun findes ét mindste primtal større end \( n\) (entydighed).
Spørgsmål c#
Kan man finde et funktionsudtryk for \(f(n)\)? Argumenter for, hvorfor det er eller ikke er muligt.
Svar
Der findes ingen kendt simpel formel, der direkte beregner det næste primtal større end et givet tal \( n\). Primtallene følger ingen enkel matematisk sammenhæng, så funktionen må beregnes algoritmisk ved at teste tal efter \(n\).
Spørgsmål d#
Implementer funktionen \(f(n)\) i Python, som tager et heltal \(n\) som input og returnerer det næste primtal større end \(n\). Definer en hjælpefunktion er_primtal(x) til at afgøre, om et tal er primtal.
from math import sqrt
def er_primtal(x: int) -> bool:
"""Returnerer True hvis x er et primtal, ellers False."""
if x < 2:
return False
# Three lines of code missing
return True
def f(n: int) -> int:
"""Returnerer det næste primtal større end n."""
kandidat = n + 1
# Two lines of code missing
return kandidat
Hint
For er_primtal(x):
Du kan undersøge om
igår op ixvedx % i == 0Tjek dette for alle
ifra2tilsqrt(x)Returner
Falsehvis det er tilfældet for eti
Hint
For f(n):
Tjek om
n+1er et primtal.Tjek nærnest om
n+2er et primtal.Osv. Stop når du finder et primtal og returner dette.
Svar
from math import sqrt
def er_primtal(x: int) -> bool:
"""Returnerer True hvis x er et primtal, ellers False."""
if x < 2:
return False
for i in range(2, int(sqrt(x)) + 1): # Vi behøver kun at tjekke op til kvadratroden af x
if x % i == 0:
return False
return True
def f(n: int) -> int:
"""Returnerer det næste primtal større end n."""
kandidat = n + 1
while not er_primtal(kandidat):
kandidat += 1
return kandidat
# Test-eksempler
if __name__ == "__main__":
n = 5
print(f"Det næste primtal større end {n} er {f(n)}.") # Skal returnere 7
n = 7
print(f"Det næste primtal større end {n} er {f(n)}.") # Skal returnere 11
Spørgsmål e#
Kan du opdatere din Python-funktion fra forrige opgave, så \(f\)’s definitionsmængde udvides fra \(\mathbb{N}\) til \(\mathbb{R}\)?
Opgaver – Lille Dag#
1: Størrelse af vektorer#
Betragt følgende tre vektorer i \(\mathbb{R}^3\):
Hvilken vektor er længst? Hvilke vektorer er ortogonale på hinanden? Hvilke to vektorer er tættest på hinanden?
Note
Vi kan forestille os vektorerne som (geometriske) stedvektorer med begyndelsespunkt i \(\pmb{0}=[0,0,0]^T\) og slutpunkt \(\pmb{v}_i\) for hhv \(i=1,2,3\). Under tiden skriver man dette som \(\overrightarrow{\pmb{0}\pmb{v}_i}\).
2: Partielle afledede af simpel skalar-funktion#
Find de partielle afledte \(\frac{\partial f}{\partial x_1}\) og \(\frac{\partial f}{\partial x_2}\) for \(f(x_1, x_2) = x_1^3 + 3x_1 x_2 + x_2^3\). Bestem værdien af de partielle afledte i punktet \((x_1,x_2)=(1,2)\).
Hint
Husk formlen for partielle afledte med hensyn til hver variabel.
Behandl andre variable som konstanter under differentiering.
Svar
\(\frac{\partial f}{\partial x_1} = 3x_1^2 + 3x_2\)
\(\frac{\partial f}{\partial x_2} = 3x_2^2 + 3x_1\)
I punktet \((1,2)\): \(\frac{\partial f}{\partial x_1}(1, 2) = 9\), \(\frac{\partial f}{\partial x_2}(1, 2) = 15\)
3: Forskellige(?) kvadratiske former#
Lad \(\pmb{x} = [x_1,x_2]^T\) være en søjlevektor i \(\mathbb{R}^2\). Definer:
og
Lad \(q_i: \mathbb{R}^2 \to \mathbb{R}\) være givet ved:
for \(i=1,2,3\). Sådanne funktioner kaldes kvadratiske former, se denne definition.
Spørgsmål a#
Gang udtrykket for \(q_1(x_1,x_2)\) ud. Først i hånden, så ved hjælp af Python. Gang også udtrykkene for \(q_2(x_1,x_2)\) og \(q_3(x_1,x_2)\) (i hånden eller Python) ud.
Hint
Det kan være nødvendigt at bruge c = Matrix([-60]) da SymPy ikke vil lægge skalarer sammen med 1x1 matricer. Omvendt, kan en 1x1 SymPy matrix q1 laves om til en skalar ved enten q1[0,0] eller q1[0].
Svar
\( q_1(\pmb{x}) = 11 x_{1}^{2} - 24 x_{1} x_{2} - 20 x_{1} + 4 x_{2}^{2} + 40 x_{2} - 60\)
Spørgsmål b#
Er den kvadratiske matrix \(A\) i en kvadratisk form (som fx \(\pmb{x}^T A \pmb{x}\)) entydig givet?
Hint
Kig på \(q_1(\pmb{x})\) og \(q_2(\pmb{x})\)
Svar
Nej. Fx er \(q_1(\pmb{x}) = q_2(\pmb{x})\), mens \(A_1 \neq A_2\).
Spørgsmål c#
Plot grafen af funktionen \(q_1\). Plot så nogle niveaukurver. Hvilken geometrisk form har niveaukurverne? Gør det samme for \(q_3\).
Spørgsmål d#
En af funktionerne har et minimum. Hvilken? Hvor ligger det cirka? Hvad kaldes det samme punkt for de funktioner der ikke har et minimum?
Svar
\(q_3\) har et minimum
Det ligger i \((2,1)\) (det skal bare aflæses fra et plot)
\(q_1\) har et såkaldt saddelpunkt i samme punkt, Wikipedia
4: Softmax-funktionen#
I denne opgave ser vi på softmax-funktionen.
Spørgsmål a#
Beregn softmax af følgende tre vektorer i \(\mathbb{R}^3\). Du kan gøre det ved håndkraft (brug lommeregner til eksponentialfunktionen) eller ved hjælp af Python. Angiv svarene med ca. 3 decimaler.
\(\pmb{x}_1=[1,2,-5]^T\)
\(\pmb{x}_2=[10,2,-5]^T\)
\(\pmb{x}_3=[100,2,-5]^T\)
Hint
Husk at \(e^{-5}\) er et meget lille tal tæt på 0. For \(\pmb{x}_3\) vil \(e^{100}\) være ekstremt stort sammenlignet med \(e^2\), hvilket vil dominere nævneren totalt.
Svar
For \(\pmb{x}_1 = [1, 2, -5]^T\): Nævneren er \(S = e^1 + e^2 + e^{-5} \approx 2.718 + 7.389 + 0.007 \approx 10.114\).
Bemærk at indeks 2 (værdien 2) har den højeste sandsynlighed.
For \(\pmb{x}_2 = [10, 2, -5]^T\): Her er \(e^{10} \approx 22026\). Nævneren domineres af dette led.
Nu har indeks 1 (værdien 10) næsten hele sandsynlighedsmassen.
For \(\pmb{x}_3 = [100, 2, -5]^T\): \(e^{100}\) er et astronomisk stort tal (\(> 10^{43}\)).
Resultatet er numerisk set en såkaldt “one-hot” vektor, der peger på maksimum.
Spørgsmål b#
Hvad observerer du, når forskellen mellem den største værdi i inputtet og de andre værdier øges (som i skiftet fra \(\pmb{x}_1\) til \(\pmb{x}_2\) og \(\pmb{x}_3\))? Hvorfor kaldes funktionen mon “soft”-max?
Svar
Når én inputværdi bliver markant større end de andre, går outputtet for denne koordinat mod 1, mens de andre går mod 0. Funktionen approksimerer altså en \(\max\)-funktion (eller mere præcist \(\text{argmax}\)), der udvælger den største værdi.
Navnet Softmax kommer af, at det er en “blød” (differentiabel) udgave af maksimums-funktionen. I stedet for at give præcis 1 på maksimum og 0 ellers (hvilket ville være et “hard” max), giver den en glattere fordeling, der fremhæver de største værdier.
Spørgsmål c#
Er softmax-funktionen kontinuert?
Spørgsmål d#
Betragt softmax som en afbildning fra \(\mathbb{R}^n\) til \(\mathbb{R}^n\). Er funktionen injektiv (en-til-en)?
Hint
Prøv at beregne softmax for \(\pmb{v}=[1,2,3]^T\) og \(\pmb{v}=[11,12,13]^T\) (hvor vi har lagt 10 til alle koordinater).
Er funktionen surjektiv (på) i forhold til dispositionsmængde \(\mathbb{R}^n\)?
Hint
Kan outputtet nogensinde indeholde negative tal eller nuller? Eller tal større end 1?
5: Kvadratiske former med symmetriske matricer#
Lad \(A\) være en vilkårlig \(n \times n\) matrix, og lad \(\pmb{x}\) være en søjlevektor i \(\mathbb{R}^n\). Definer \(B\) ved \(B = (A + A^T)/2\).
Spørgsmål a#
Vis at matricen \(B\) er symmetrisk.
Hint
En matrix \(B\) er symmetrisk hvis og kun hvis \(B = B^T\). Husk at \(B = \tfrac{1}{2} (A + A^T) \)
Svar
\( B^T = ((A + A^T)/2)^T = \tfrac{1}{2} (A^T + (A^T)^T) = \tfrac{1}{2} (A^T + A) = \tfrac{1}{2} (A + A^T) = B \)
Spørgsmål b#
Vis at \(\pmb{x}^T A \pmb{x} = \pmb{x}^T B \pmb{x}\).
Spørgsmål c#
Konkludér at man altid kan antage at kvadratiske former af formen \(q(\pmb{x}) = \pmb{x}^T A \pmb{x} + \pmb{b}^T \pmb{x} + c\) er givet ved en symmetrisk matrix \(A\).